




Not too long ago, we explored JavaScript Proxies and the Reflect API, discussing their benefits and illustrating their potential through a straightforward book rating application. The goal was to provide a gentle introduction to these powerful features. However, after publishing that article, I received an insightful comment from a reader who suggested that the example provided might not be the best showcase of Proxies' true potential.
That comment sparked my curiosity and inspired me to dig deeper into the world of JavaScript Proxies. As a result, I created this follow-up article, focusing on more advanced use cases and practical scenarios to demonstrate the true power of Proxies in real-world applications. This discussion will be valuable for readers familiar with Proxies and those eager to learn how they can be effectively utilized.
This article will briefly revisit the concept of JavaScript Proxies and their purpose. We will then dive into practical use cases, providing detailed code examples and clear explanations. By the end of this journey, you should have a comprehensive understanding of how Proxies can solve various problems and optimize your applications.
So, without further ado, let's continue our adventure into the fascinating world of JavaScript Proxies and discover their true potential in real-world scenarios!
JavaScript Proxies
Let’s briefly revise the definition of JavaScript Proxies before we dive deep into the use cases.
Proxies act as intermediaries between objects and their interactions, allowing developers to intercept and modify actions such as getting or setting properties or calling functions. The purpose of Proxies is to enhance various aspects of application development, such as validation, encapsulation, and code maintainability.
Here's the basic syntax for creating a JavaScript proxy:
const targetObject = {
// properties and methods
};
const handler = {
// traps for intercepting operations on the target object
};
const proxy = new Proxy(targetObject, handler);
By harnessing the power of Proxies, you can create more efficient, clean, and organized code, ultimately improving your applications and deepening your understanding of JavaScript's capabilities.
Data Binding and Access Control
Proxies can be effectively used to implement both data binding and access control. Let’s implement this by defining a createReactiveStore function that takes an initial data object and sets up a Proxy with a handler to manage data binding and access control.
function createReactiveStore(data) {
const observers = [];
function addObserver(observer) {
observers.push(observer);
}
function notifyObservers(changes) {
observers.forEach(observer => observer(changes));
}
const handler = {
set(target, prop, value) {
const oldValue = target[prop];
const success = Reflect.set(target, prop, value);
if (success && oldValue !== value) {
notifyObservers({ prop, oldValue, newValue: value });
}
return success;
},
get(target, prop, receiver) {
if (prop.startsWith('_')) {
throw new Error(`Access denied: ${prop} is a private property`);
}
return Reflect.get(target, prop, receiver);
}
};
const proxy = new Proxy(data, handler);
return { data: proxy, addObserver };
}
const data = {
name: 'John Doe',
age: 25,
_privateInfo: { ssn: '123-45-6789' }
};
const store = createReactiveStore(data);
store.addObserver(changes => {
console.log('Data changed:', changes);
});
store.data.age = 30; // Notifies the observer
try {
console.log(store.data._privateInfo); // Throws an error
} catch (error) {
console.error(error.message);
}
The output:

In this example, we define a createReactiveStore function that takes an initial data object and sets up a Proxy with a handler to manage data binding and access control. The handler notifies all registered observers when a property change and restricts access to properties that start with an underscore, treating them as private.
A practical use case of the createReactiveStore will be in a data visualization dashboard. By using createReactiveStore in a data visualization dashboard, you can efficiently manage dynamic data and ensure that visualizations are always up-to-date, providing your users with a real-time view of the data.
Let’s use Chartjs to demonstrate this.
<html lang="en">
<body>
<canvas id="barChart"></canvas>
<script src="<https://cdn.jsdelivr.net/npm/chart.js>"></script>
<script src="app.js"></script>
</body>
</html>
In the app.js let’s create the createReactiveStore function and initialize the data store:
function createReactiveStore(initialData) {
const observers = new Set();
const handler = {
set(target, prop, value) {
target[prop] = value;
observers.forEach(observer => observer());
return true;
}
};
const addObserver = (observer) => {
observers.add(observer);
};
return {
data: new Proxy(initialData, handler),
addObserver
};
}
const initialData = {
dailyActiveUsers: [50, 60, 70, 80, 90, 100, 110]
};
const store = createReactiveStore(initialData);
Here, initialData is an object with a single property, dailyActiveUsers, which is an array of numbers. The createReactiveStore function is called with initialData to create a reactive data store named store. The store object has a data property that is a proxy to the initialData object and an addObserver method to add observer functions. When a change is made to the store.data, all observer functions will be called.
Next, let's create the bar chart using Chart.js and connect it to the reactive store:
const chartElement = document.getElementById('barChart').getContext('2d');
const barChart = new Chart(chartElement, {
type: 'bar',
data: {
labels: ['Sunday', 'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday'],
datasets: [{
label: 'Daily Active Users',
data: store.data.dailyActiveUsers,
backgroundColor: 'rgba(75, 192, 192, 0.2)',
borderColor: 'rgba(75, 192, 192, 1)',
borderWidth: 1
}]
},
options: {
scales: {
y: {
beginAtZero: true
}
}
}
});
function updateChartData() {
barChart.data.datasets[0].data = store.data.dailyActiveUsers;
barChart.update();
}
store.addObserver(updateChartData);
This is what happens here:
The HTML element with the ID 'barChart' is selected, and its 2D context is retrieved, which is required for rendering the chart.
A bar chart is initialized using the
Chartconstructor, providing it with the chart element's context, the chart type ('bar'), and data fromstore.data.dailyActiveUsers.The
updateChartDatafunction is defined, which is responsible for updating the chart's data with the latest information from the reactive store and triggering a chart update. This function ensures the chart stays in sync with the data store.The
updateChartDatafunction is added as an observer to the reactive store by callingstore.addObserver(updateChartData). This action ensures that theupdateChartDatafunction is called whenever the reactive store's data changes, keeping the chart up-to-date with the latest data.
Finally, let's simulate receiving new data and updating the reactive store:
setTimeout(() => {
store.data.dailyActiveUsers = [60, 70, 80, 90, 100, 110, 120];
}, 2000);
Output:
Initial data:
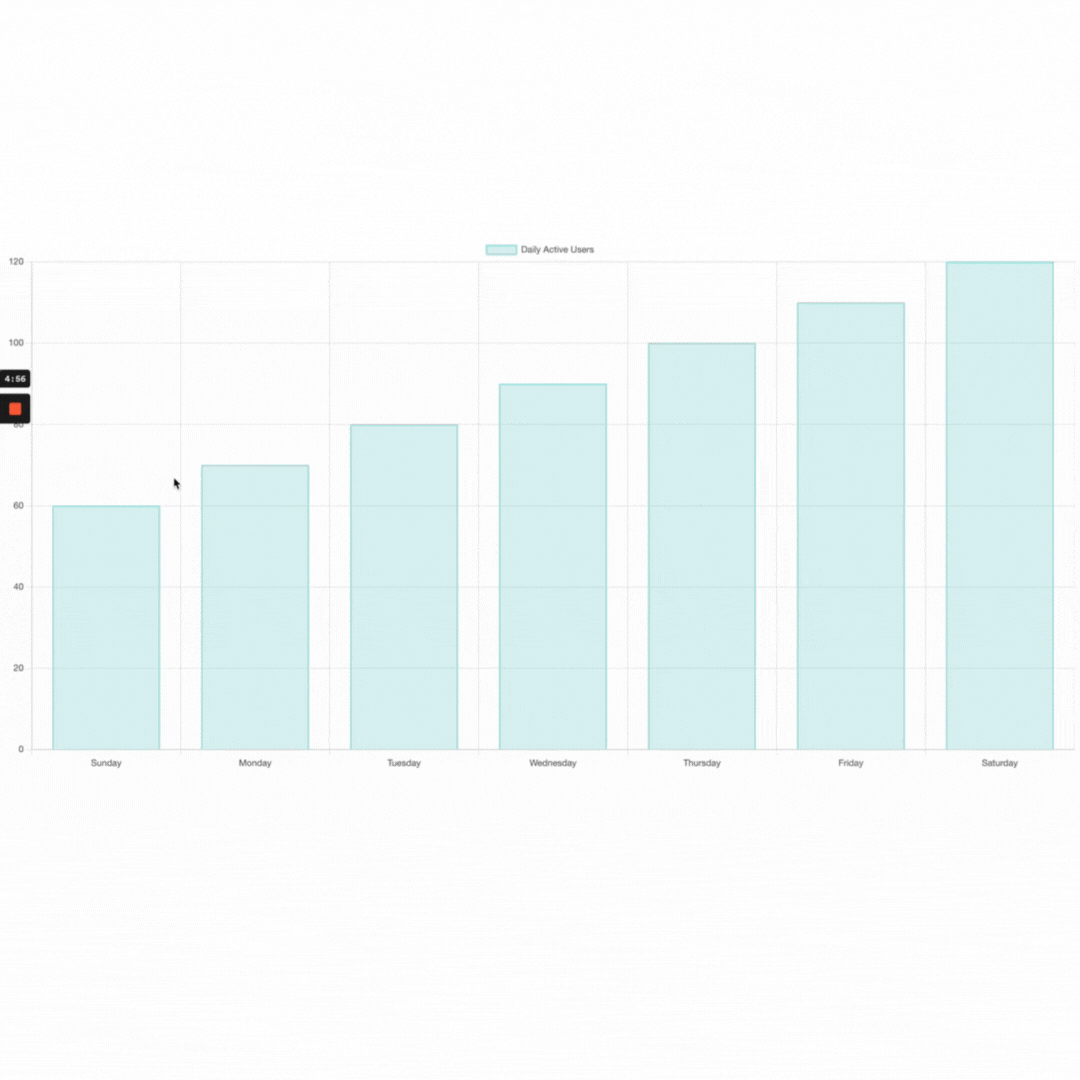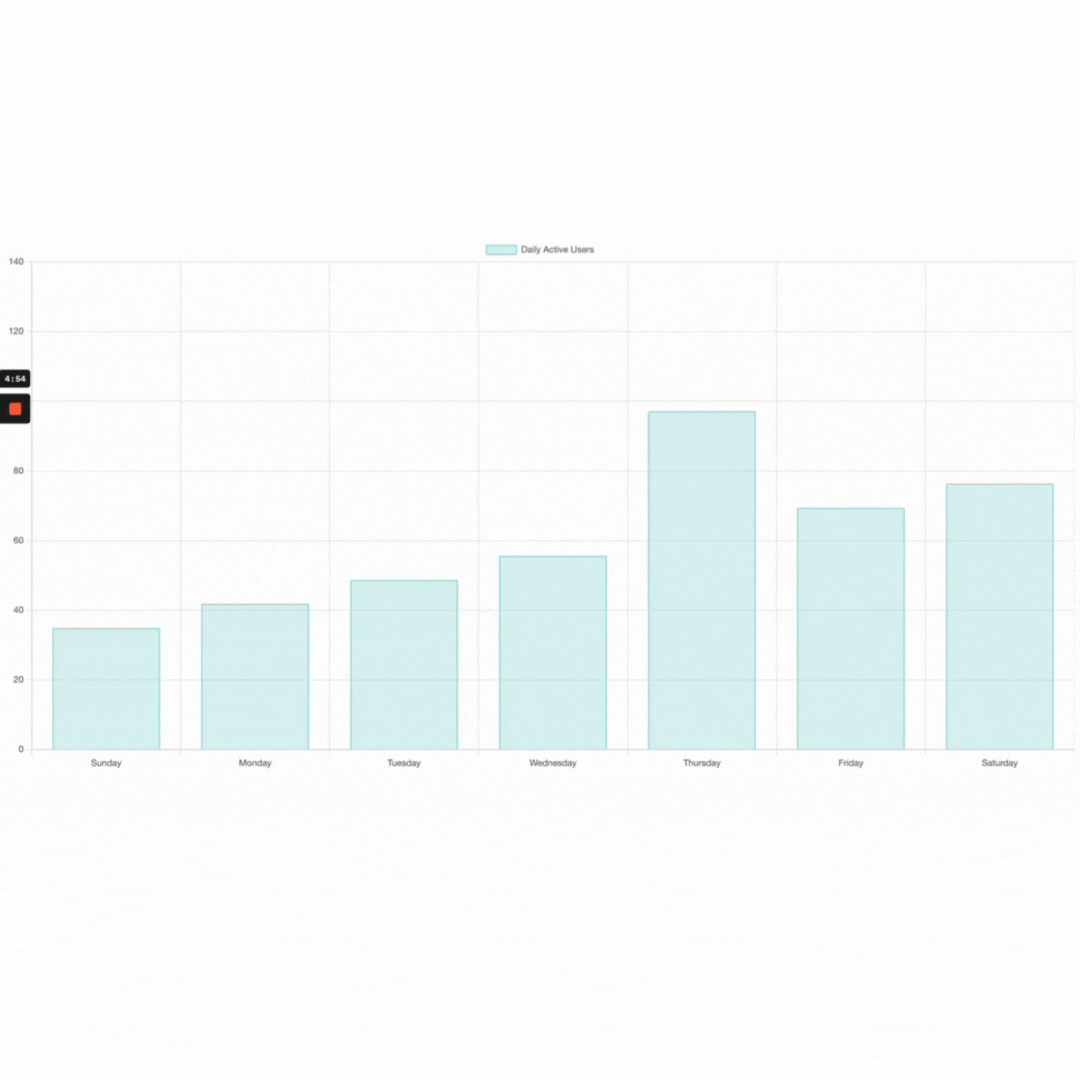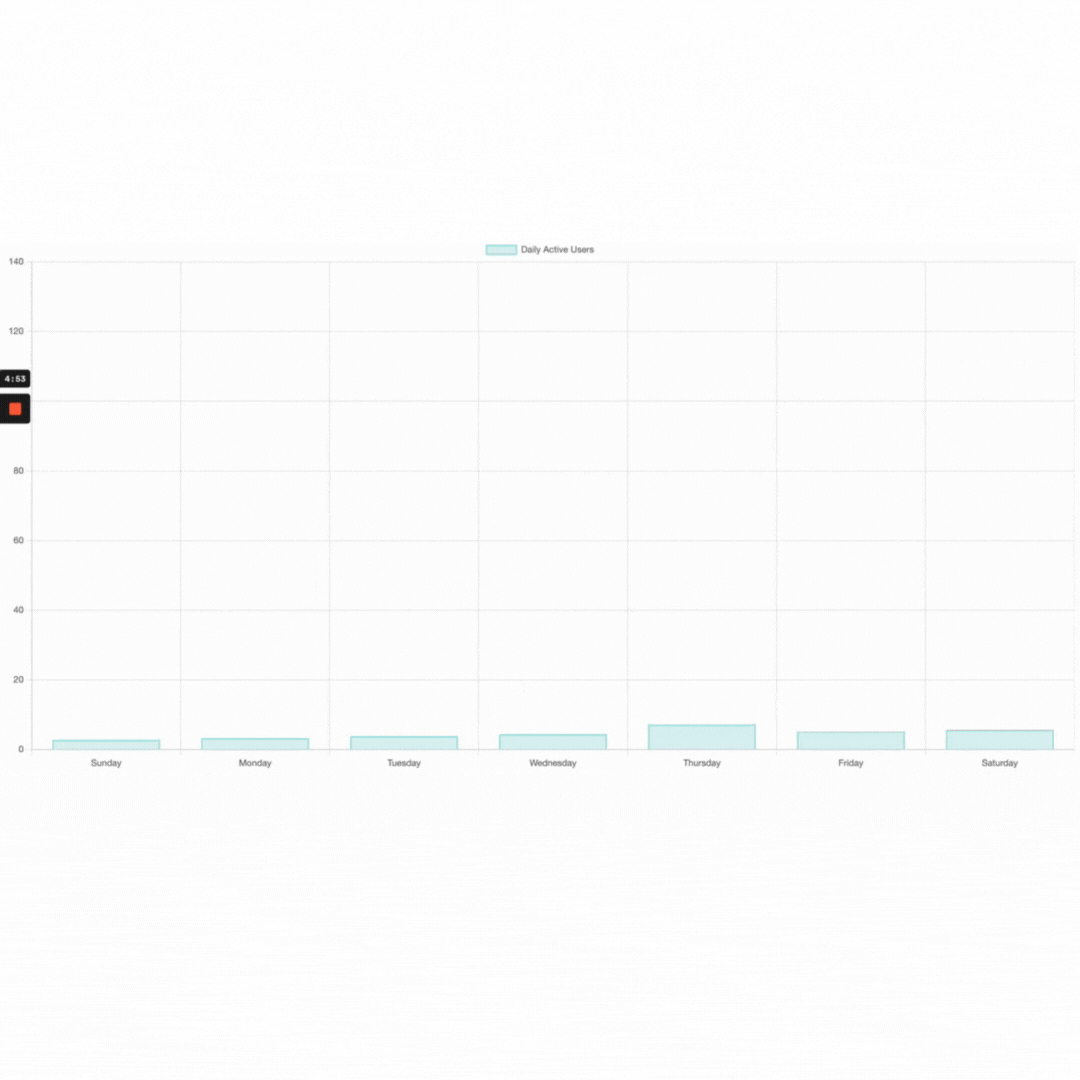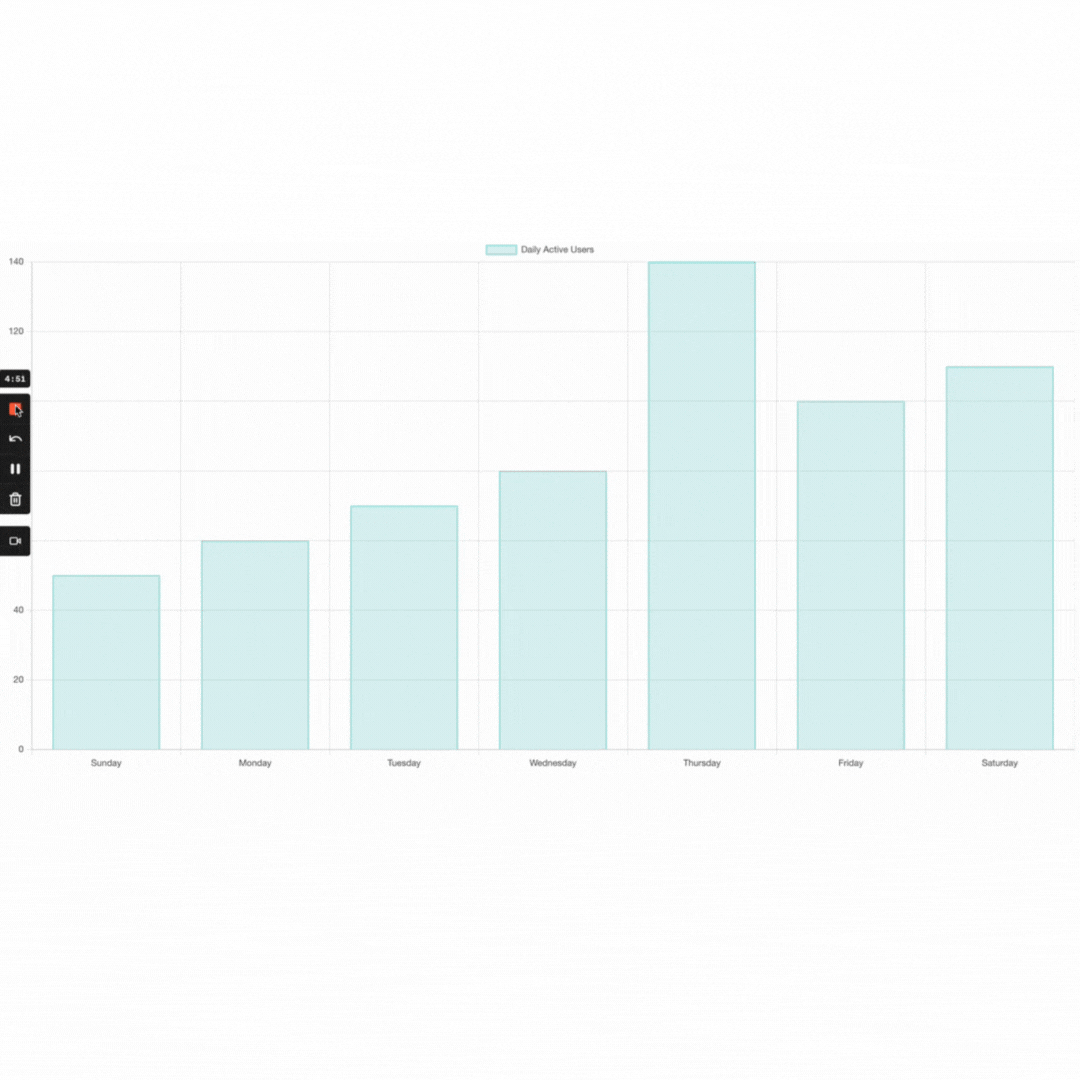
Alternative Approaches
Yes, there are several alternative ways to create reactive data stores without using Proxy . One common approach is to use getter and setter functions to intercept changes to the data like this:
function createReactiveStore(initialData) {
const observers = new Set();
const data = { ...initialData };
const addObserver = (observer) => {
observers.add(observer);
};
const notifyObservers = () => {
observers.forEach(observer => observer());
};
const set = (prop, value) => {
data[prop] = value;
notifyObservers();
};
const get = (prop) => {
return data[prop];
};
return {
data,
addObserver,
set,
get
};
}
In this approach, regular object data is used instead of a Proxy. Changes are intercepted using a set function that updates the data object and subsequently notifies any registered observers rather than utilizing a set trap. Additionally, a get function retrieves values from the data object.
However, while this approach works well for simple use cases, it has some limitations. For example, it requires that you manually define getter and setter functions for every property you want to make reactive, whereas with Proxy, you can make an entire object reactive with a single new Proxy() call. Additionally, it can be more verbose and less flexible than using Proxy.
Memoization and Caching
Another use case for JavaScript Proxies is memoization and caching. Memoization is an optimization technique that stores the results of expensive function calls and returns the cached result when the same inputs occur again. This can significantly improve performance by avoiding repetitive and time-consuming calculations.
With Proxies, you can create a memoization cache by intercepting the function calls and storing the results of those calls with specific arguments. Let's dive into an example to see how this works.
Consider a recursive function to calculate the factorial of a number, which can be quite expensive for large input values:
function factorial(n) {
if (n === 0) {
return 1;
}
return n * factorial(n - 1);
}
Now, let's create a memoization function that takes the original function as an argument and returns a Proxy to that function:
function memoize(func) {
const cache = new Map();
const handler = {
apply(target, thisArg, args) {
const key = JSON.stringify(args);
if (cache.has(key)) {
return cache.get(key);
}
const result = target.apply(thisArg, args);
cache.set(key, result);
return result;
}
};
return new Proxy(func, handler);
}
const memoizedFactorial = memoize(factorial);
Here, the memoize function creates a Map named cache to store the results of the function calls. A Proxy is then created with a handler that intercepts the apply method. When a function call is made, the handler checks if the result for the given arguments is already in the cache. If it is, the cached result is returned; otherwise, the function is called, and the result is stored in the cache before returning it.
Now, the memoizedFactorial function can be used just like the original factorial function, but with the added benefit of memorization:
console.log(memoizedFactorial(5));
console.log(memoizedFactorial(5));
console.log(memoizedFactorial(6));

A practical use case of this will be when you want to limit cache size or implement a cache eviction policy (e.g., Least Recently Used (LRU) or First-In-First-Out (FIFO)), you can extend the memoization function to include such policies.
Using JavaScript Proxies, let's explore a real-world use case with cache eviction policies. We will create a memoization proxy with a TTL-based eviction policy for caching the results of an API call to fetch weather data.
First, let's create an API wrapper for fetching weather data:
async function fetchWeatherData(city) {
// Simulate an API call with a delay
await new Promise(resolve => setTimeout(resolve, 1000));
// Mocked weather data
const data = {
'New York': { temperature: 75, condition: 'Sunny' },
'San Francisco': { temperature: 68, condition: 'Cloudy' },
'Tokyo': { temperature: 60, condition: 'Rainy' }
};
return data[city] || { error: 'City not found' };
}
Now, let's create a function to create a memoization proxy with a TTL-based eviction policy:
function createMemoizationProxy(fetchFn, ttl) {
const cache = new Map();
return new Proxy(fetchFn, {
async apply(target, thisArg, args) {
const key = JSON.stringify(args);
if (cache.has(key)) {
const cachedData = cache.get(key);
// Check if the cached data has expired
if (Date.now() - cachedData.timestamp < ttl) {
console.log('Cache hit:', key);
return cachedData.data;
} else {
console.log('Cache expired:', key);
cache.delete(key);
}
}
const data = await Reflect.apply(target, thisArg, args);
cache.set(key, { data, timestamp: Date.now() });
console.log('Cache set:', key);
return data;
}
});
}
This code snippet defines a createMemoizationProxy function that takes a fetchFn function and a time-to-live (ttl) value as arguments. The purpose of this function is to create a memoization proxy that caches the results of the fetchFn function for a specified period (ttl).
Here’s a step-by-step overview of the implementation:
A
cacheis created using aMapobject to store the fetched data along with their timestamps.The
createMemoizationProxyfunction returns a newProxyobject with thefetchFnas the target and a custom handler object.The
handlerobject has anapplymethod that intercepts the function calls made to thefetchFn. Theapplymethod takes three parameters:target(the original function),thisArg(thethiscontext), andargs(the function call arguments).The
argsare serialized into a string (key) to be used as the cache key.The cached data is retrieved if the
keyis found in the cache. If the cached data hasn't expired (determined by comparing the current timestamp with the cached timestamp and thettlvalue), the cached data is returned, and a "Cache hit" message is logged. If the cached data has expired, it is removed from the cache, and a "Cache expired" message is logged.If there's no cache hit or the cache has expired, the original
fetchFnfunction is called with theargsusingReflect.apply. The result is stored in thedatavariable.The newly fetched
data, along with the current timestamp, is added to the cache, and a "Cache set" message is logged.
The proxy will handle caching and cache expiration, ensuring that repeated calls to the function with the same arguments return the cached data if it's still valid, improving the performance of your application.
Now, let's create a memoized version of the fetchWeatherData function with a TTL of 10 seconds:
const memoizedFetchWeatherData = createMemoizationProxy(fetchWeatherData, 60000);

Alternative Approach with Closures
A common alternative is to use a closure that captures the cache inside the function itself. Here's an example:
function createMemoizationFunction(fetchFn, ttl) {
const cache = new Map();
return async function(...args) {
const key = JSON.stringify(args);
if (cache.has(key)) {
const cachedData = cache.get(key);
if (Date.now() - cachedData.timestamp < ttl) {
console.log('Cache hit:', key);
return cachedData.data;
} else {
console.log('Cache expired:', key);
cache.delete(key);
}
}
const data = await fetchFn(...args);
cache.set(key, { data, timestamp: Date.now() });
console.log('Cache set:', key);
return data;
};
}
Whether you use Proxies or Closures for memoization and caching, both approaches works well and have their merits. You might prefer Proxies because:
It allows you to create a more flexible and reusable caching mechanism that can be applied to a broader range of functions or objects.
or if you want to apply caching to multiple functions without duplicating the caching logic.
Easier debugging would lean me toward the Proxy approach. This is because, With a Proxy, you can easily log cache hits, misses, and evictions. The Proxy handler contains the caching logic, making it easier to understand and debug the caching behavior.
However, the choice between the two depends on your specific use case, personal preference, and familiarity with the techniques.
Remote Procedure Call (RPC) with Web Workers
Jos de (creator of the workerpool library) inspired this use case. He commented:
As for a good example: I’ve used Proxy in one occasion so far where I found it truly useful: in my workerpool library, where you can invoke methods on a dynamic, remote object in a Web Worker via a proxy. Basically: RPC to some remote process or backend.
RPC is a communication protocol used for calling a function in a different process or on a remote computer. RPC allows you to abstract the communication details and make the function appear to be being called locally. With JavaScript Proxies, you can implement RPC to enable seamless communication between the main thread and a Web Worker.
Web Workers provide a way to run JavaScript code in a separate thread, allowing you to offload computationally heavy tasks without blocking the main thread. However, communication between the main thread and a Web Worker is usually done through the postMessage method and event listeners, which can be cumbersome to manage.
Using JavaScript Proxies, you can create an RPC interface for your Web Worker that allows calling functions as if they were local. Let's see an example of how this works.
First, create a Web Worker file named worker.js:
self.onmessage = function (event) {
const { id, method, args } = event.data;
if (typeof self[method] === 'function') {
self[method](...args)
.then((result) => {
self.postMessage({ id, result });
})
.catch((error) => {
self.postMessage({ id, error });
});
} else {
self.postMessage({ id, error: 'Method not found' });
}
};
async function expensiveTask(duration) {
await new Promise((resolve) => setTimeout(resolve, duration));
return `Task completed after ${duration}ms`;
}
This Web Worker listens for incoming messages, extracts the id, method, and args from the message data, and tries to call the corresponding method with the provided arguments. If the method call succeeds, it returns a message to the main thread with the result and the same id. If an error occurs, it sends back the error message.
Now, in your main JavaScript file, create an RPC Proxy for the Web Worker:
function createRpcProxy(worker) {
const handler = {
get(target, method) {
return function (...args) {
return new Promise((resolve, reject) => {
const id = Date.now() + Math.random().toString(36).substr(2);
worker.onmessage = function (event) {
const { id: responseId, result, error } = event.data;
if (responseId === id) {
if (error) {
reject(new Error(error));
} else {
resolve(result);
}
}
};
worker.postMessage({ id, method, args });
});
};
},
};
return new Proxy({}, handler);
}
const worker = new Worker('worker.js');
const rpcProxy = createRpcProxy(worker);
The createRpcProxy function takes a Web Worker as an argument and returns a Proxy with a custom handler. The handler intercepts property access and returns a function that sends a message to the worker with the id, method, and args. It then listens for a response from the worker with the same id and resolves or rejects the promise accordingly.
You can now use the rpcProxy to call functions in the Web Worker as if they were local
rpcProxy.expensiveTask(2000)
.then((result) => {
resultDiv.textContent = result;
})
.catch((error) => {
resultDiv.textContent = `Error: ${error.message}`;
});
The rpcProxy.expensiveTask function call is proxied to the Web Worker, which executes the expensiveTask function without blocking the main thread.

Making Asynchronous API calls is a practical use case of RPC with Web workers. Let's consider a web application that fetches data from multiple APIs simultaneously. By distributing the API requests across multiple Web Workers using the worker pool library, we can improve the application's overall performance by parallelizing network requests.
First, let's create a worker script (worker.js) that will handle making the API calls:
importScripts('<https://unpkg.com/workerpool@6.1.2/dist/workerpool.min.js>');
async function fetchData(url) {
const response = await fetch(url);
const data = await response.json();
return data;
}
// Register the fetchData function with the workerpool
workerpool.worker({
fetchData
});
Now, let's create the main application script (app.js) that will use the workerpool library to distribute API requests across multiple workers:
// Create a worker pool
const pool = workerpool.pool('worker.js');
function createRpcProxy(pool) {
return new Proxy(
{},
{
get(target, prop, receiver) {
return async function (...args) {
const result = await pool.exec(prop, args);
return result;
};
},
}
);
}
const rpcProxy = createRpcProxy(pool);
const apiUrls = [
'<https://jsonplaceholder.typicode.com/posts/1>',
'<https://jsonplaceholder.typicode.com/posts/2>',
'<https://jsonplaceholder.typicode.com/posts/3>',
];
Promise.all(apiUrls.map(fetchApi))
.then((results) => {
console.log("API responses:", results);
})
.catch((error) => {
console.error("Error fetching data:", error);
})
.finally(() => {
pool.terminate();
});
async function fetchApi(url) {
const result = await rpcProxy.fetchApi(url);
return result;
}
In this implementation, we use workerpool and Proxies to create an RPC-like interface for the Web Workers. This makes it easy to communicate with the workers and execute tasks without worrying about the underlying message passing mechanism.
Here is a step-by-step overview of this implementation:
A worker pool is created using
workerpool.pool('worker.js'), initializing a pool of Web Workers that execute the code inworker.jsA
createRpcProxy()function is defined, taking a worker pool as its argument. This function returns a Proxy that intercepts property access and turns it into remote function calls on the worker pool.Inside the Proxy handler, a
gettrap is present. When a property (in this case, a function) is accessed on the Proxy, thegettrap is triggered. It returns anasyncfunction that, when called, usespool.exec()to execute the corresponding function in the worker pool.When the
fetchApi()function is called in the main thread, it uses therpcProxyto execute thefetchApi()function in the worker pool. TherpcProxyabstracts away the message passing between the main thread and the worker pool, making the process of offloading tasks to Web Workers seamless and more convenient.’’
Output:

Alternative Approaches
A few alternative approaches exist to implement parallel network requests in a web application. Some of them include:
Simple
fetch()orXMLHttpRequestcalls without Web Workers: This approach involves making multiple API requests directly from the main thread. While this is simpler to implement, it can lead to performance issues if the main thread becomes blocked or if there is significant processing involved with the API responses.Manual management of Web Workers: Instead of using the
workerpoollibrary, you can manually create and manage Web Workers. This involves handling message passing between the main and worker threads and managing the worker's lifecycle. While this approach provides more control over the Web Workers, it can become complex and difficult to maintain as the application grows.
This is why I prefer the workerpool and Proxies implementation:
Efficient worker management: The workerpool library handles Web Workers' creation, management, and termination efficiently. It takes care of the worker's lifecycle, ensuring optimal resource usage.
Simplified communication: JavaScript Proxies simplify the communication between the main thread and the worker threads by abstracting away the message-passing mechanism. This makes the code easier to understand and maintain.
Scalability: As the application grows, workerpool and Proxies can scale to handle increased complexity and parallelism. This approach can also be combined with other optimization techniques to improve performance further.
Other Practical Use Cases of Proxies
Here are some other acceptable use cases of JavaScript proxies:
API Wrappers and Interceptors: Proxies can be used to create API wrappers that intercept requests and responses. This enables the addition of custom logic, such as error handling, authentication, or request/response transformation, without modifying the original API call.
Virtual DOM: Proxies can help create a virtual DOM to track changes to the actual DOM efficiently. By intercepting property access and modification, proxies can record differences between the virtual and real DOMs, enabling efficient updates and reducing unnecessary rendering.
Dependency Injection: Proxies can implement dependency injection in JavaScript applications. By intercepting constructor calls and property access, proxies can inject dependencies into classes or objects, improving the modularity and testability of the code.
The complete code examples are here on this Github Repo.
Wrapping up…
This article has explored a range of practical use cases, including data binding and access control, memoization and caching, and remote procedure calls with Web Workers. The flexibility and potential of JavaScript Proxies open up numerous opportunities for optimizing, simplifying, and enhancing your JavaScript codebase.
Resources
MDN Web Docs - Proxy: The official Mozilla Developer Network (MDN) documentation on JavaScript Proxies.
JavaScript Proxy API: A detailed guide on JavaScript Proxies from the Exploring ES6 book by Dr. Axel Rauschmayer.
JavaScript Proxy Playground: An interactive tutorial on JavaScript Proxies allows you to experiment with different examples and understand how Proxies work.