




Imagine your Node.js application struggling to keep up as user requests pile up, creating a performance bottleneck that no developer wants to face. This is a common challenge in single-threaded Node.js applications. But fear not; robust solutions exist to break free from these limitations. In this article, we'll delve into three powerful strategies to supercharge your Node.js API: Node.js clustering to leverage multiple CPU cores, load testing with Autocannon to measure performance, and advanced optimizations like Least Recently Used (LRU) caching and logging.
Prerequisites
To follow along with this article, you’ll need to have the following:
- Node.js and npm installed
- Basic understanding of TypeScript and Express.js
- Clone the starter repository and switch to the starter branch: GitHub Repo
Understanding Node.js Clustering
Think of Node.js clustering as a team of workers in a factory assembly line. In a single-threaded environment, just one worker (or CPU core) does all the tasks. This lone worker can get overwhelmed, leading to performance bottlenecks. Imagine multiplying that worker to fully utilize all the available assembly lines (or CPU cores). That's what Node.js clustering does—it distributes incoming network requests across multiple CPU cores, making your application more scalable and efficient.
The importance of Node.js clustering can't be overstated. It's like upgrading from a one-man shop to a full-fledged factory. Distributing tasks speeds up the production line and makes it more resilient. If one worker fails, others can pick up the slack, ensuring your API remains responsive even under heavy load.
Let's examine how clustering is implemented in your cloned starter branch app.ts. The relevant part is as follows:
import cluster from 'cluster';
import os from 'os';
const numCPUs = os.cpus().length;
if (cluster.isMaster) {
logger.info(`Master ${process.pid} is running`);
// Fork workers
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker) => {
logger.error(`Worker ${worker.process.pid} died`);
});
}
In this snippet, we first import the cluster and os modules. We then determine the number of CPU cores available on the machine using os.cpus().length. If the code runs on the master process, it forks a worker for each CPU core. This way, we can fully utilize the multi-core capabilities of modern CPUs to improve the performance of our Node.js application.
When you run the project with npm run dev, you should see this:
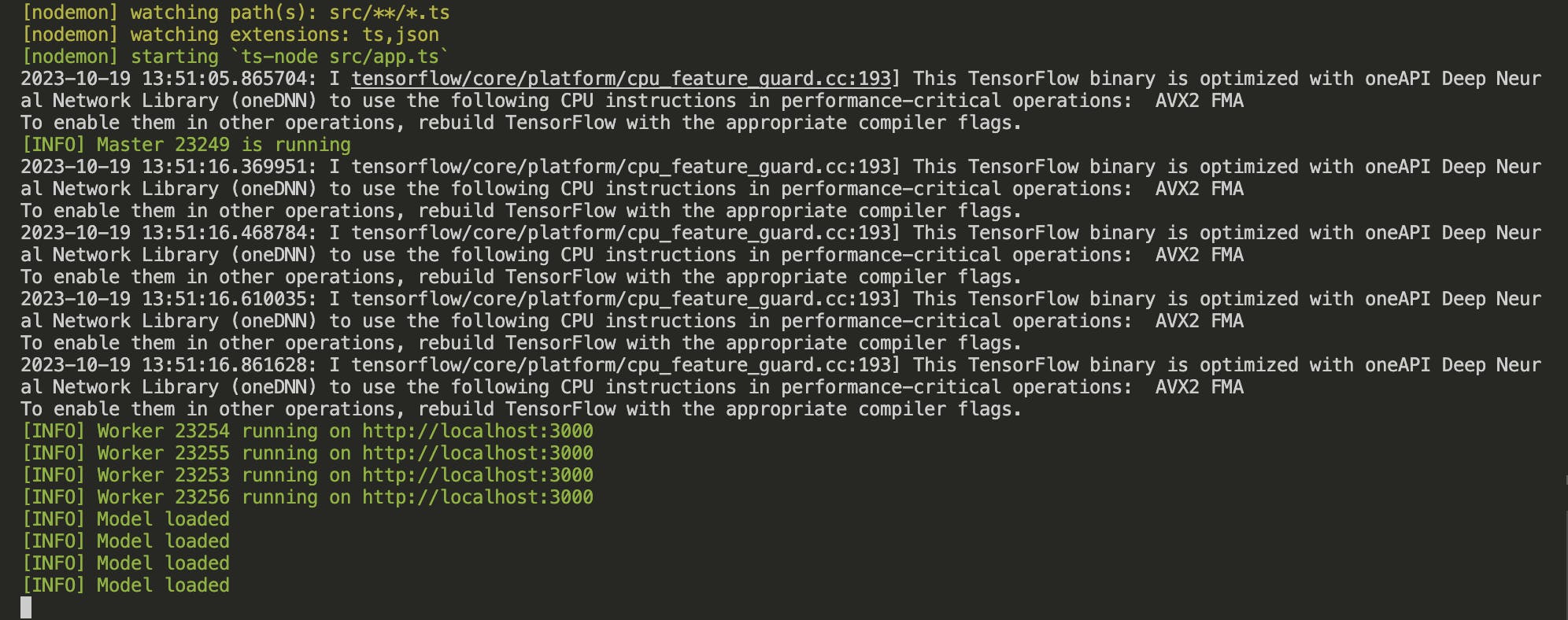
These logs confirm that your application is running in a clustered mode, utilizing all available CPU cores. Each worker is equipped with an instance of the TensorFlow model, ready to handle incoming requests. Let’s break it down:
- Master is Running: The
[INFO] Master 23249 is runningmessage signifies that the master process has successfully started. The number23249is the process ID of the master. - Workers are Running: Messages like
[INFO] Worker 23254 running on http://localhost:3000indicate that worker processes have been forked and are running. Each worker listens on the same port (3000in this case). The numbers23254,23255, etc., are the process IDs of the workers. - Model Loaded: The
[INFO] Model loadedmessages confirm that the TensorFlow model has been successfully loaded into each worker. This is crucial because each worker will handle incoming requests independently.
Load Testing with Autocannon
Imagine your API as a busy highway. You've added more lanes (workers) to handle traffic, but how do you know it's enough? Well, that’s where you need to load-test your API. To do that, we’ll use Autocannon. Autocannon is a fast HTTP/1.1 benchmarking tool powered by Node.js. It's like a traffic simulator for your API, allowing you to understand how your application performs under different load levels.
Setting Up Autocannon
First, you'll need to install Autocannon. You can do this by running npm install autocannon in your terminal. Once installed, you can create an autocannon-test.js** and add these lines of code:
const autocannon = require('autocannon');
const fs = require('fs');
const boundary = '----WebKitFormBoundary7MA4YWxkTrZu0gW';
const filePath = '/Users/mac/Desktop/sammy23/image-recognition-api/image1.png';
const fileContent = fs.readFileSync(filePath);
const body = Buffer.concat([
Buffer.from(
`--${boundary}\r\n` +
'Content-Disposition: form-data; name="image"; filename="image1.png"\r\n' +
'Content-Type: image/png\r\n' +
'\r\n'
),
fileContent,
Buffer.from(`\r\n--${boundary}--\r\n`)
]);
const instance = autocannon({
url: 'http://localhost:3000/upload',
method: 'POST',
connections: 10,
duration: 60,
headers: {
'Content-Type': `multipart/form-data; boundary=${boundary}`
},
body: body
}, (err, result) => {
if (err) {
console.error('Error running autocannon:', err);
} else {
console.log('Test completed:', result);
}
});
autocannon.track(instance, { renderProgressBar: true }); ****
In the autocannon-test.js file, you'll see several key components:
- File and Boundary Setup: The
boundaryandfilePathvariables define the multipart form boundary and the path to the image file you'll upload. ThefileContentreads the image file into a buffer. - HTTP Request Configuration: The
instanceobject specifies the test parameters. Theurlis where the API is running,methodis POST, andconnectionsanddurationdefine the load you want to simulate. - Headers and Body: The
headersandbodyfields in theinstanceobject specify the HTTP headers and the request's body. The body is a buffer that includes the image file and the multipart form boundary. - Running and Tracking: The
autocannon()function runs the test andautocannon.track(instance, { renderProgressBar: true })tracks the progress.
After running node autocannon-test.js, you'll see a comprehensive output showing your API's performance.
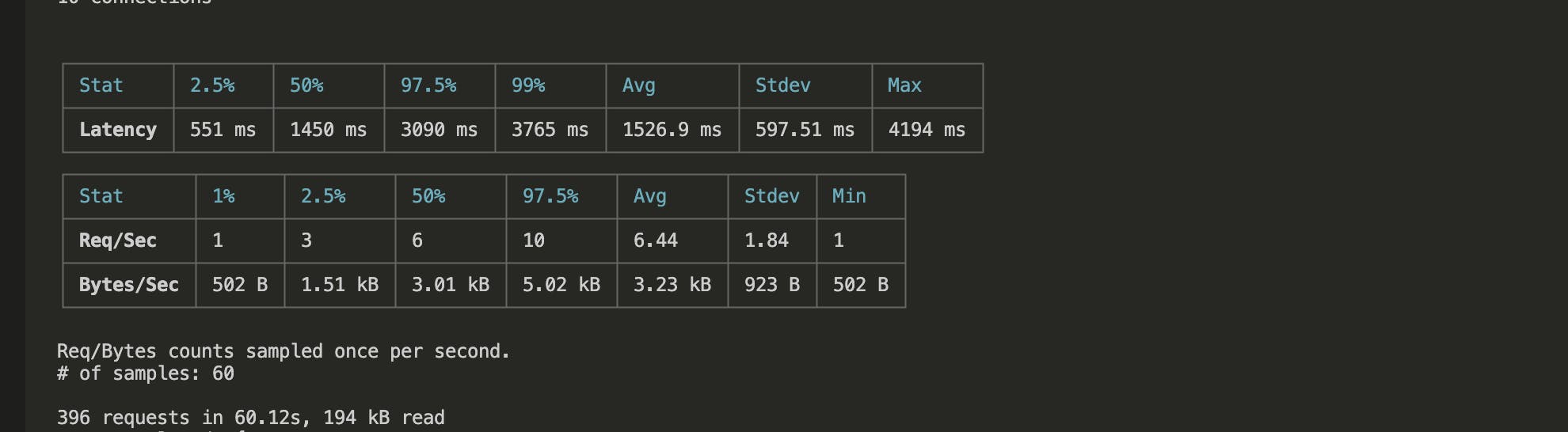
The average latency is 1526.9 ms, and the API can manage an average of 6.44 requests per second. The "2xx" count of 386 confirms that most requests were successful, indicating a stable API under load.
The latency and throughput metrics offer a nuanced view of your API's behavior. For instance, 50% of the requests have a latency less than or equal to 1450 ms, and 99% are under 3765 ms. These figures help you identify bottlenecks and make informed decisions for further optimizations, ensuring that your API can handle real-world usage patterns effectively.
Advanced Caching with LRU Cache
To further improve the performance of the Image Recognition API, we’ll add some advanced optimization techniques. One of those techniques is the Least Recently Used (LRU) Caching. LRU caching keeps recently used data closer (in memory), so when the same data is requested again, the system doesn't have to go through the lengthy process of fetching it from the source.
For this sample codebase, we’ll use a basic implementation of LRU caching:
const options = {
max: 500, // The maximum number of items to store in the cache
maxAge: 1000 * 60 * 30 // Items expire after 30 minutes
};
const classificationCache = new LRUCache(options);
// ... (other parts of the code)
const imageId = req.file.filename;
const cachedResult = classificationCache.get(imageId);
if (cachedResult) {
return res.json({ predictions: cachedResult });
}
// ... (other parts of the code)
classificationCache.set(imageId, predictions);
In the code above, we initialize an LRU cache with a maximum of 500 items and a 30-minute expiration time for each item. When an image is uploaded for classification, the API first checks if the result is already in the cache (classificationCache.get(imageId)). If it is, the cached result is returned, saving computational time. If not, the image is processed, and the result is stored in the cache (classificationCache.set(imageId, predictions)).
The LRU cache is a performance booster for this image recognition API, particularly useful when dealing with repetitive image classifications. Imagine a scenario where the same images are uploaded and classified multiple times. Without caching, the API would redundantly perform the same computationally expensive TensorFlow operations for each request, leading to higher latency and increased CPU load.
By implementing LRU caching, we store the classification results of recently processed images. When the API receives a request to classify an image it has seen recently, it can simply retrieve the result from the cache instead of re-running the classification. This significantly reduces the API's response time and lightens the load on the CPU, making the system more efficient and scalable.
Conclusion
In large Node.js applications, clustering is an indispensable tool for harnessing the full power of your machine's CPU cores. It's not just about making your application faster; it's about making it resilient and capable of handling an increasing number of requests without choking. By distributing the load across multiple worker processes, you can ensure your application remains responsive even under heavy stress.
This article explored the essential techniques for optimizing a Node.js API. We delved into clustering to improve performance, used Autocannon for load testing, and implemented LRU caching to reduce redundant operations.
Resources
For those eager to dive deeper into the topics covered, here are some additional resources that can further your understanding and skills:
- Node.js Clustering:
- Load Testing with Autocannon:
- LRU Caching:
- Logging and Monitoring:
- TensorFlow.js and MobileNet: